Attention 注意力机制
传统的 Seq2Seq 模型中,编码器在处理源句时,无论其长度如何,最终都只能将整句信息压缩为一个固定长度的上下文向量,用作解码器的唯一参考。这种设计存在两个显著问题:
- 信息压缩困难:固定向量难以完整表达长句或复杂语义,容易丢失关键信息;
- 缺乏动态感知:解码器在每一步生成中都只能依赖同一个上下文向量,难以根据不同位置的生成需要灵活提取信息。
为了解决上述问题,研究者引入了 Attention 机制。其核心思想是:
解码器在生成目标序列的每一步时,不再依赖于一个静态的上下文向量,而是根据当前的解码状态,动态地从编码器各时间步的隐藏状态中选取最相关的信息,以辅助当前步的生成。
这种机制赋予模型“对齐”能力,使其能够自动判断源句中哪些位置对当前的目标词更为重要,从而有效缓解信息瓶颈问题,提升生成质量与表达能力。
一、Attention 原理
注意力机制的核心思想,是解码器在生成目标序列的每一步时,动态地从编码器的各个时间步的隐藏状态中提取当前所需的信息,而不再只依赖一个固定的上下文向量。
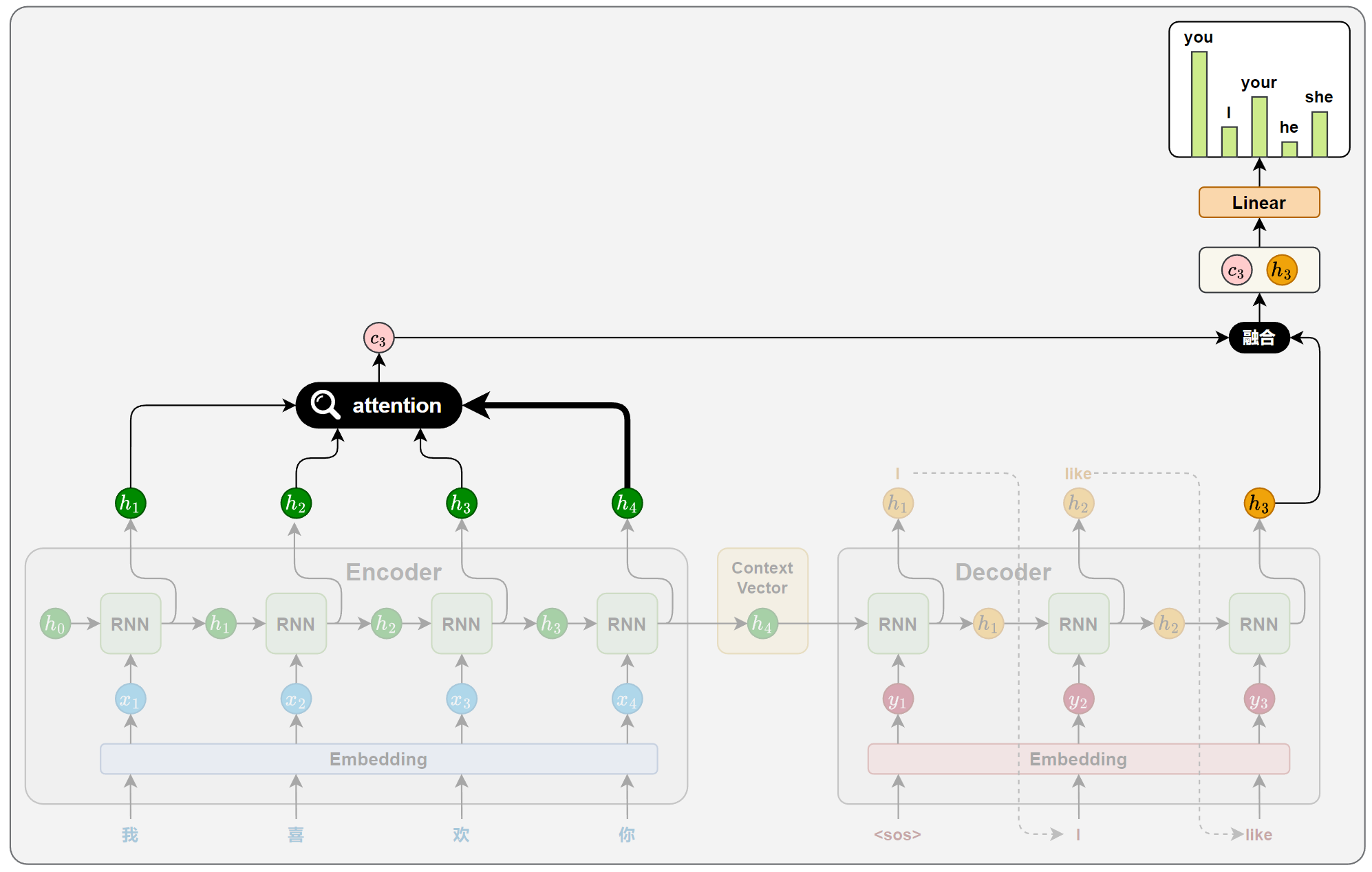
这一机制通常通过以下 4 个关键步骤实现:
1.相关性计算
在目标序列生成的每一步,解码器都会计算当前时间步的隐藏状态与编码器各个时间步输出之间的相关性。这些相关性衡量了源句中每个位置对当前生成内容的重要程度,从而决定模型应将多少注意力分配给不同的源位置。
相关性的计算依赖于特定的函数,通常被称为注意力评分函数(attention scoring function)。
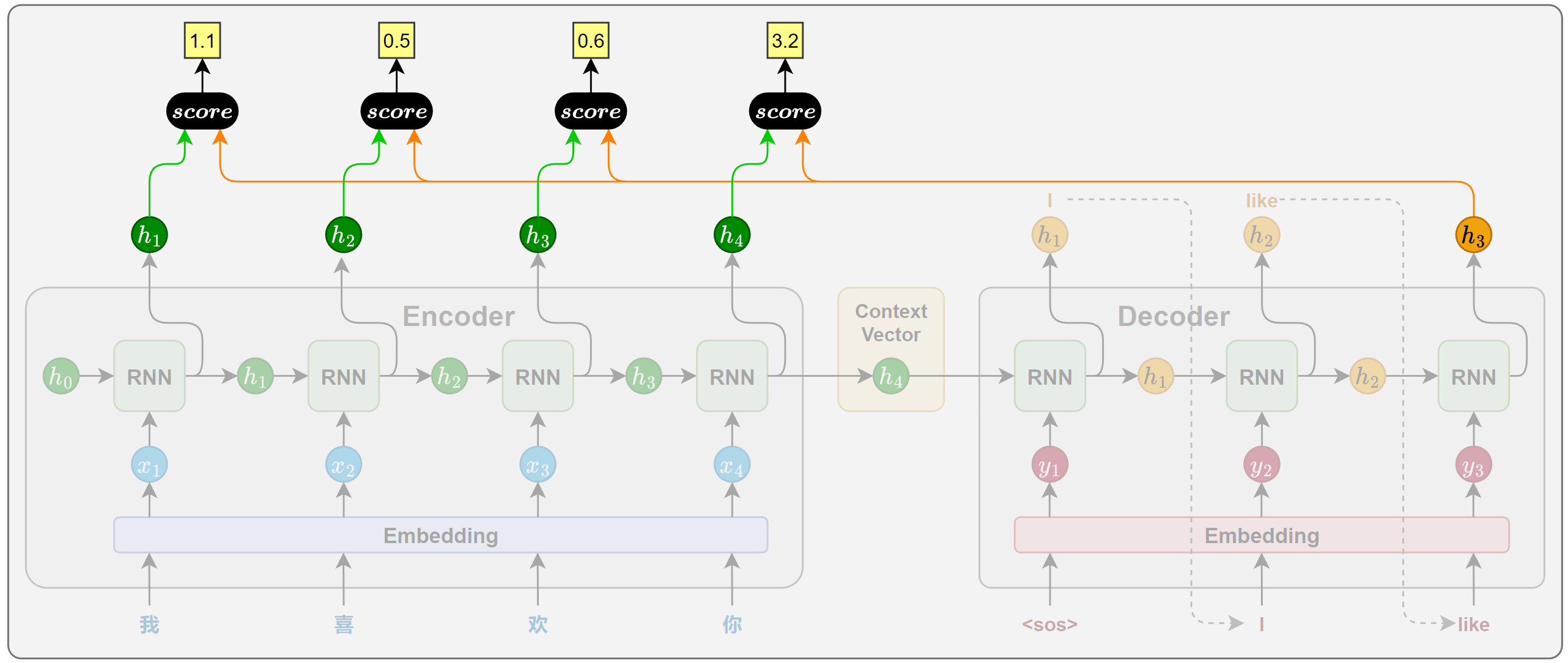
2.注意力权重计算
得到所有源位置的注意力评分后,使用 Softmax 函数将其归一化为概率分布,作为注意力权重。得分越高的位置,其对应的权重越大,代表模型在当前生成中更关注该位置的信息。
3.上下文向量计算
将所有编码器输出按照注意力权重进行加权求和,得到一个上下文向量。这个向量就表示当前时间步,模型从源句中提取出的关键信息。