预训练模型
早期的自然语言处理方法通常针对每个具体任务单独训练模型,且严重依赖大量人工标注数据。虽然在部分场景下效果可观,但也暴露出显著局限:
- 语言知识难以复用: 每个模型都需从零开始训练,导致训练成本高、效率低;
- 强依赖高质量标注: 在医疗、法律等专业领域,标注数据获取困难且代价高昂。为解决这些问题,研究者提出了新的建模范式——“预训练 + 微调”:
- 预训练阶段: 在大规模未标注语料上训练语言模型,学习词汇、句法和上下文等通用语言规律;
- 微调阶段: 将预训练模型迁移至具体任务,仅需少量标注数据即可完成任务适配。
这一方法显著提升了模型的通用性和开发效率,已成为当前 NLP 的主流技术路线,并广泛应用于文本分类、问答系统、翻译、对话等任务中。
一、预训练模型分类
预训练语言模型几乎都构建在 Transformer 架构之上。相较于传统的循环神经网络,Transformer具有以下优势:
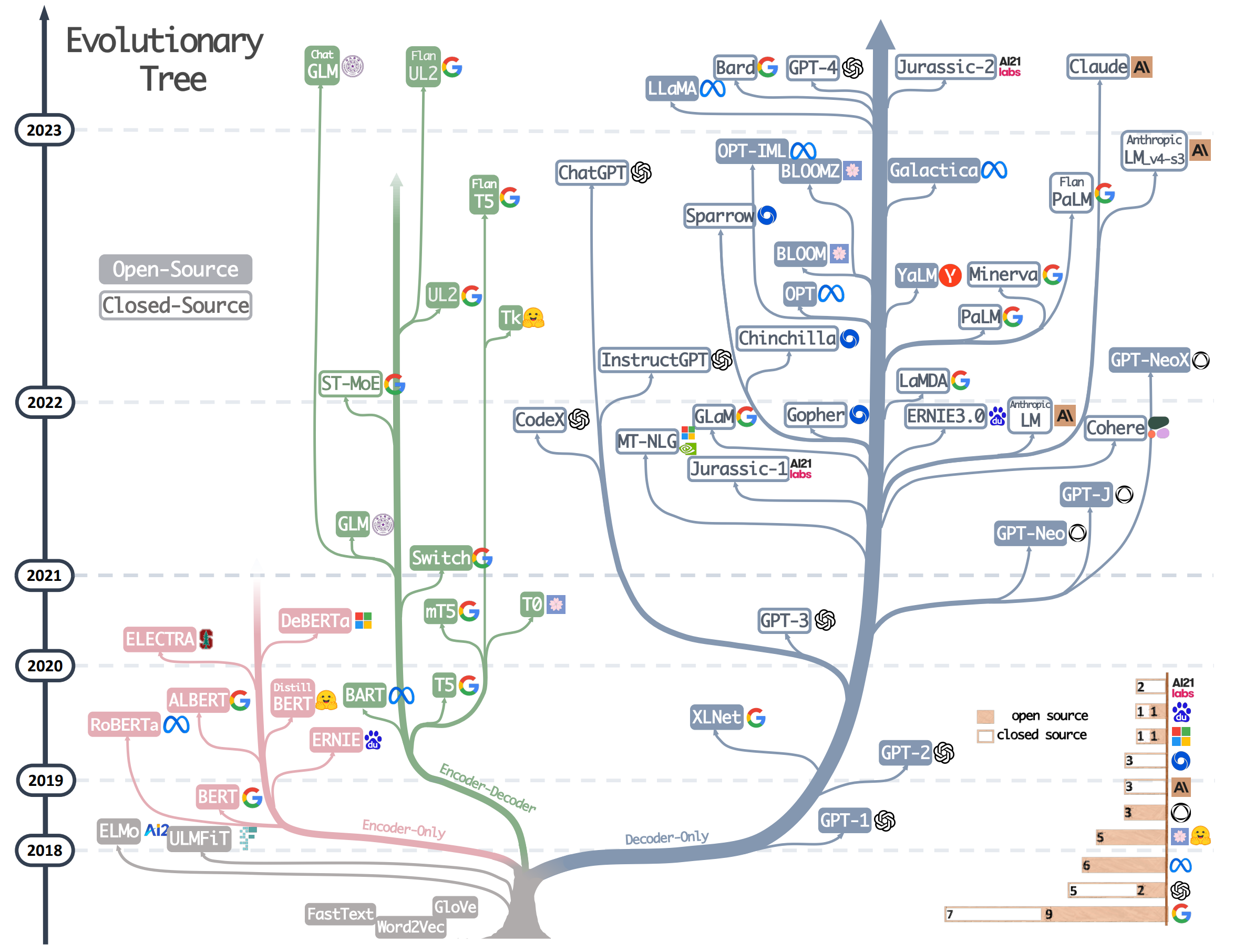
自 GPT、BERT 和 T5 等模型发布以来,基于 Transformer 的预训练模型不断涌现,模型架构和能力持续演进。下图总结了 2018 年至 2023 年间具有代表性的模型及其发展脉络。